
표준국어대사전
 국립국어원의 표준국어대사전 2002년판은 동아출판사에서 사전으로 배포했다. 그러나 최근에 완성된 표준국어대사전은 이렇게 배포하지 않고 있다. 오로지 표준국어대사전 사이트를 통해서만 사전을 사용할 수 있다. 물론 PC에 설치해서 사용할 수 있는 프로그램도 있다. 그러나 이 프로그램도 표준국어대사전 사이트를 검색한 결과를 되돌려 주는 것에 불과하다. 따라서 표준국어대사전을 딕셔너리 유니버샬에서 사용할 수 있는 사전 파일로 만들기 위해서는 클리핑(Clipping) 작업이 필수적이다.
국립국어원의 표준국어대사전 2002년판은 동아출판사에서 사전으로 배포했다. 그러나 최근에 완성된 표준국어대사전은 이렇게 배포하지 않고 있다. 오로지 표준국어대사전 사이트를 통해서만 사전을 사용할 수 있다. 물론 PC에 설치해서 사용할 수 있는 프로그램도 있다. 그러나 이 프로그램도 표준국어대사전 사이트를 검색한 결과를 되돌려 주는 것에 불과하다. 따라서 표준국어대사전을 딕셔너리 유니버샬에서 사용할 수 있는 사전 파일로 만들기 위해서는 클리핑(Clipping) 작업이 필수적이다.
목차
사전 만들기
- iPod Touch 강좌 51. 사전 만들기 1. 소개 국립국어원의 표준국어대사전은 표제어의 수가 50... 새창
- iPod Touch 강좌 55. 사전 만들기 3. 컴파일 이번에는 사전 만들기의 세번째 강좌로 클리핑된 ... 새창
- iPod Touch 강좌 56. 사전 만들기 4. 설치 아이팟 터치(iPod Touch)를 사용하면서 사전 어플... 새창
- iPod Touch 강좌 57. 사전 만들기 5. 옛... 이번 글은 사전 만들기의 마지막 강좌이다. 사전... 새창
클리핑
아이팟 터치(iPod Touch)용 표준국어대사전 기능은 이전 강좌에서 소개했다. 따라서 이 글에서는 사전에 대한 간단한 소개와 클리핑하는 방법을 이야기하겠다. '아이팟 터치'용 표준국어대사전은 이미지를 지원하며 표제어가 51'0440개인 아주 방대한 사전이다. 웹 데이타를 그대로 따왔기 때문에 아이팟 터치용 사전 치고는 예쁘며 파일 크기가 상당히 크다. 이미지를 포함한 사전 파일은 총 566M에 달한다. 사전에 이미지를 포함하고 있기 때문에 weDict에서는 사용할 수 없고 오로지 딕셔너리 유니버샬(Dictionary Universal)에서만 사용할 수 있다.


먼저 가장 왼쪽의 그림은 딕셔너리 유니버셜에 등록되어 있는 사전들이다. 두번째 그림은 표준국어대사전에 대한 간단한 정보이다. 표제어의 수는 스타딕 사전 파일을 만들면 자동으로 추가된다. 사전 이름과 설명은 정보 파일을 직접 편집해서 추가한 것이다. 표준국어대사전을 클리핑하다 보면 재미있는 단어들이 많았다.
먼저 행사다. 행사는 우리말로는 '어떤 일을 시행함. 또는 그 일.'이라고 정의돠어 있지만 북한말로는 '국가나 사회단체 따위가 일정한 계기와 목적 밑에 특별히 조직하는 대중 정치사상 사업의 하나', '기껏하여 한다는 일이나 짓.'이라고 한다. 행정편의주의 때문에 갖은 전시행사가 열리는 우리나라에서 보면 우리말 정의 보다는 북한말 정의가 더 가슴에 와닿는다. 또 사전을 만들다 보니 후장총이라는 단어도 있었다. '후장'이 가지는 비속어 이미지가 있기 때문에 이 단어 자체가 조금은 우수웠다. 아무튼 완성된 사전의 파일의 정보는 다음과 같다.
| 파일 | 크기 | 설명 |
|---|---|---|
| KSD2009.dict | 408,417,612 | 사전 정보를 담고 있는 메인 사전 파일 |
| KSD2009.idx | 9899794 | 표제어 색인을 담고 있는 인덱스 파일 |
| KSD2009.ifo | 985 | 사전 설명과 사전에 대한 정보를 담고 있는 정보 파일 |
| res | 177,011,084 | 총 9189개 이미지를 저장하고 있는 이미지 폴더 |
| KSD2009.tar.bz2 | 197,218,769 | 스타딕 배포본 형태로 압축한 파일 |
표준국어대사전
국립국어원의 표준국어대사전 2002년판은 동아출판사에서 사전으로 배포했다. 그러나 최근 완성된 표준국어대사전은 이렇게 배포하지 않고 있다. 오로지 표준국어대사전 사이트를 통해서만 사전을 사용할 수 있다. 물론 PC에 설치해서 사용할 수 있는 프로그램도 있지만 이 프로그램도 표준국어대사전 사이트를 검색한 결과를 되돌려 주는 것에 불과하다. 따라서 표준국어대사전을 딕셔너리 유니버샬에서 사용할 수 있는 사전 파일로 만들기 위해서는 클리핑(Clipping) 작업이 필수적이다.
표준국어대사전의 클리핑 주소는 http://stdweb2.korean.go.kr/search/View.jsp?idx=1로서 'idx'의 값을 1에서 518063까지 바꾸면 '총 510440개 표제어'를 클리핑할 수 있다. 또 클리핑을 하다 보면 중간에 빠지는 주소가 종종 나타난다. 과거에 표준국어대사전에 등록했지만 표준이라는 말에 걸맞지 않아 삭제한 것으로 보인다. 이렇게 빠진 데이타는 다음과 같다. 5만개 단위로 클리핑했기 때문에 5만개 단위로 빠진 인덱스를 추가했다.
| 순번 | 범위 | 순번 | 범위 |
|---|---|---|---|
| 50000 | 50000-887=49113 | 350000 | 50000-634=49366 |
| 100000 | 50000-798=49202 | 400000 | 50000-780=49220 |
| 150000 | 50000-734=49266 | 450000 | 50000-659=49341 |
| 200000 | 50000-697=49303 | 500000 | 50000-596=49404 |
| 250000 | 50000-738=49262 | 518063 | 18063-405=17658 |
| 300000 | 50000-695=49305 | 총 | 518063-7623=510440 |
클리핑 방법
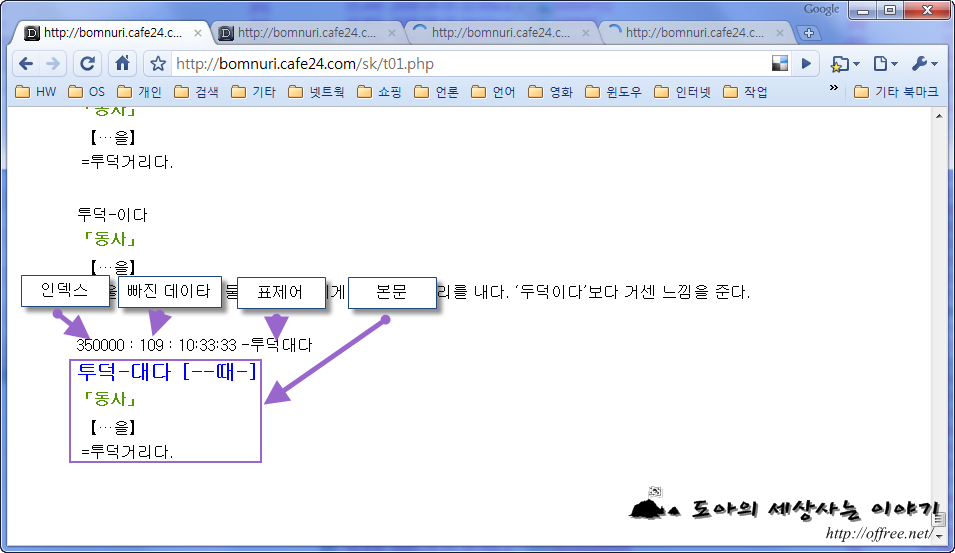
클리핑하는 방법은 간단하다. 다음 그림은 표준국어대사전에서 불국사 페이지를 인덱스로 연 뒤 소스 보기를 한 것이다.

① ①에서 ^를 제거한 뒤 표제어로 사용한다.
② ①과 ②를 합쳐서 사전 페이지의 제목으로 사용한다.
③ ③은 설명으로 사용한다. 다만 이렇게 하면 웹 페이지처럼 표시되지 않기 때문에 'class' 속성 대신에 'style' 속성으로 바꿔야 한다.
④ ④는 이미지이다. 이 주소를 그대로 사용해도 되지만 인터넷 연결이 끊기면 그림이 표시되지 않는다. 따라서 이 부분은 filename.jpg로 바꾸고 사전 폴더에 'res'라는 하위 폴더를 만들고 이 폴더에 filename.jpg를 넣어두면 딕셔너리 유니버샬(Dictionary Universal)이 알아서 이미지를 가져온다.
이렇게 클리핑한 데이타를 표제어, 탭, 설명순으로 두면 사전 파일의 한 행이 만들어 진다.
불국사다보탑 <div style='font-weight: bold; font-size: 20px; color: #0000ff; font-family: AppleGothic, nGulim;'>불국사^다보탑(佛國寺多寶塔)</div><span style="font-family:tahoma; font-weight:bold;color:#549606; padding-top:-10px; margin-bottom:-0.1;vertical-align:top">「고적」</span><br><ul style="font-family:AppleGothic, Sans-serif;color:#000000; line-height:1.5; padding:5px;list-style: none;"><li><span style="width:45px; font-weight:bold;color:#cb4a00;vertical-align:top; text-align:right"> </span>경주 불국사 경내에 있는 대웅전 앞에 있는 두 탑 중 동쪽에 있는 탑. 통일 신라 경덕왕 10년(751)에 건립된 것으로 추정된다. 높이는 10.4미터 정도이며 화강암으로 되어 있다. 국보 제20호. ≒다보탑「1」. <br></li></ul><center><img src='fd009sz.jpg' width='300'><br></center>
여기서 'font-family'에서 'AppleGothic' 다음에 'nGulim'을 추가한 이유는 nGulim이 고어를 지원하기 때문이다. 즉, 일반문자는 AppleGothic으로 표시하고 고어는 nGulim으로 표시하게 된다. 이런 작업을 idx 1부터 518063까지 하면 된다. 사전 파일에 한글이 포함되면 반드시 파일을 UTF-8로 저장(dict, ifo 모두 해당)해야 한다. 그렇지 않으면 글자가 깨지거나 잘못된 사전 파일로 뜬다. 당연한 이야기지만 이 작업은 수작업으로 할 수는 없다. 따라서 주변에 프로그램을 짤 줄 아는 사람이 있다면 부탁하는 것이 좋다.
클리핑 어플
나는 PHP로 간단한 클리핑 프로그램을 짠 뒤 한번에 5만개씩 가져오도록 했다. 1000개의 데이타를 30분에 가져오기 때문에 52만개를 가져오려고 하면 총 10일 20시간이 걸린다. 이런 문제 때문에 총 6개의 프로그램을 돌려 이틀 동안 클리핑했다. 이 과정에서 프로그램 오류, 브라우저 오류로 약 100만개의 크리핑 데이타[1]를 날렸다. 즉, 프로그램을 이용해도 쉬운 작업은 아니었다.
프로그램을 짤 줄 모르고 주변에 아는 프로그래머도 없다면 내가 짠 프로그램을 사용해도 된다. 단순히 클리핑을 위해 짠 프로그램이라 소스를 이해하기 조금 힘들 수 있다. 다만 주의할 것은 '이 프로그램에 대한 어떠한 질문도 받지 않는다'는 점이다. 따라서 자기 호스팅 서버에 이 프로그램을 돌려보고 동작하면 웃고 그렇지 않으면 지우면 된다. 아울러 이 프로그램에 대한 질문이 올라오면 답하지 않고 바로 삭제할 생각이다.
프로그램 받기: ClippingKSD.php
프로그램 보기
이 프로그램은 HTML에서 데이타를 정확히 클리핑하기 위해 PHP Simple HTML DOM Parser라는 해석기를 이용한다. 따라서 이 어플을 저장한 폴더에 'simple_html_dom.php' 파일도 함께 넣어 두어야 한다. 이 파일은 PHP Simple HTML DOM Parser 사이트에서 'simplehtmldom_1_11.zip'을 내려받으면 구할 수 있다.
클리핑 데이타
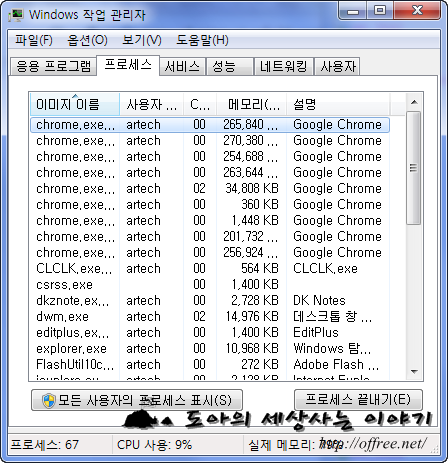
위의 어플을 적당한 이름(예: ClippingKSD.php)으로 저장한 뒤 자신이 운영하는 웹 사이트에 올린다. 그리고 [tg=Chrome]크롬/tg과 같은 브라우저로 PHP 프로그램을 호출하면 어플과 같은 폴더에 'koreaNNNNNN.txt'와 같은 파일이 만들어 진다. 생성 모드가 아니라 추가 모드이기 때문에 클리핑 중간에 브라우저가 죽었다면 어플 소스에서 $min 값만 적당한 값으로 바꿔 다시 실행하면 된다.
 클리핑 어플 실행 결과
클리핑 어플 실행 결과
 클리핑된 원시 데이타
클리핑된 원시 데이타
파일의 생성일자를 보면 알 수 있지만 9월 5일 부터 오늘까지 클리핑한 것을 알 수 있다. 5만개씩 6개, 두번을 클리핑했기 때문에 이론상 40시간이 걸린다.
위 그림은 이렇게 클리핑한 원시 데이타이다. 이 데이타를 합치고 스타딕 편집기로 불러와 Build만 하면 사전 파일이 만들어 진다. 다만 처음 어플을 짤 때 고어까지 함께 표시하는 방법을 생각하지 못해 위의 어플을 이용하면 스타일에 'nGulim'이 추가되지 않는다. 또 본문에 포함된 수식이 여러 개면 인터넷 주소가 그대로 남는다. 이런 문제 때문에 어플을 바꾸거나 나중에 EditPlus와 같은 편집기로 한번 다시 가공 해주어야 한다. 다음 그림은 이렇게 재가공된 클리핑 데이타이다.
 재가공된 클리핑 데이타
재가공된 클리핑 데이타
따로 올릴 필요는 없지만 소스를 그대로 이용하면 꼭 '재가공'해 주어야 한다는 것을 강조하기 위해 올렸다.
무서운 저작권법
이런 클리핑 프로그램을 제공하는 것 보다는 '스타딕 사전 파일을 제공하는 것'이 글을 쓰는 나나 사전을 쓸 사람이나 서로 편하다. 그런데 굳이 방법도 복잡한 클리핑 방법을 소개하는 이유는 간단하다. 우리나라의 저작권법이 너무 무섭기 때문이다. '우리나라의 저작권법은 저작자와 사용자 모두를 보호하지 못한다'. 오로지 묻지마 고소를 일삼는 법무법인과 힘있는 사람들에게만 도움이 된다.
그래서 이 사전 파일은 어떤 경우에도 공개하지 않을 생각이다. 삼자 고발까지 가능한 상황이라면 이런 저작권에 문제가 있을 수 있는 파일을 올리는 것 자체가 사이트를 닫는 첩경[2]이기 때문이다. 따라서 이 사전 파일에 대한 요청도 위 어플과 마찬가지로 받지 않을 생각이다. 또 안면이 있다고 요청해도 줄 생각은 없다. 사전 파일 정보에 필명과 블로그 주소를 넣은 것도 이런 의지를 반영하고 싶었기 때문이다. 따라서 이 사전이 필요한 사람은 직접 클리핑해서 사용하기 바란다.
남은 이야기
크롬, 오페라, 불여우를 이용해서 클리핑을 시도했다. 이 과정에 크롬이 얼마나 신뢰성있는 브라우저인지 다시 한번 확인하는 계기가 됐다. 그 이유는 다음과 같은 상황이 발생했기 때문이다.
2만개의 데이타 클리핑(크롬 6개, 파폭 6개)
총 1000개의 데이타를 클리핑하는데 걸리는 시간은 30분 정도다. 따라서 한시간에 2000개가 가능하다. 2만개는 10시간 분량이고 6개의 탭을 이용했기 때문에 브라우저당 총 12만개를 클리핑하게 된다. 크롬과 불여우로 동시에 걸었기 때문에 총 24만개의 클리핑이 가능하다. 일단 걸어놓고 퇴근한 뒤 확인해 보니 크롬은 12만개를 모두 클리핑했다. 반면 파폭은 오류를 내뱉고 죽어있었다. 즉, 메모리 사용량이 증가하면 서로 다른 프로세스로 동작하는 크롬은 아무 문제 없이 동작했지만 불여우에서는 문제가 생기는 듯 했다.
5만개의 데이타 클리핑(크롬 6개, 오페라 6개)
한 시간에 2000개가 가능하기 때문에 5만개의 데이타는 총 25시간이 걸린다. 크롬에 6개 탭으로 1~30만까지를 클리핑하도록 하고 오페라로 30만부터 52만까지 클리핑하도록 했다. 50~52만까지의 데이타는 데이타량이 적기 때문에 전날 완료됐다. 그리고 퇴근한 뒤 출근해 보니 컴퓨터가 장난 아니게 느렸다. 확인해 보니 크롬은 각 프로세스당 200M에서 300M의 메모리를 차지하고 있었고 오페라는 약 1G의 메모리를 차지하고 있었다.
시스템이 너무 느려 일단 크롬을 중지한 뒤 다시 클리핑 하도록 했다. 그리고 지금까지 크리핑된 데이타를 확인해봤다. 크롬으로 클리핑한 데이타는 완벽했다. 클리핑 개수와 빠진 인덱스 모두 일치했다. 그런데 오페라로 클리핑한 자료는 조금 문제가 있었다. 확인해 보니 오페라는 상당히 많은 데이타를 반복 클리핑하고 있었다. 즉 데이타를 요청하다 일정 시간이 지나면 다시 데이타를 요청했기 때문에 발생한 현상으로 보였다. 중요한 것은 모든 데이타를 이렇게 클리핑한 것이 아니라 일부 데이타(35~40만까지, 오페라가 오동작하기 전에 죽은 탭)는 정상적으로 클리핑한 것이 확인되었다.
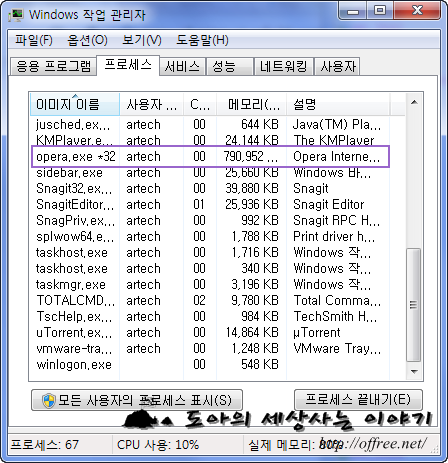
1만개의 데이타 클리핑(크롬 6개, 사파리 4개)
오페라가 실패한 뒤 이번에는 사파리로 해봤다. 기본 엔진이 같기 때문에 괜찮을 것으로 생각했다. 처음에는 사파리도 잘 동작했다. 그리고 시간이 지남에 따라 취소하지 않았는데도 불구하고 데이타를 가져오지 못하는 탭이 있다는 것을 발견했다. 결국 크롬으로 5만개를 모두 클리핑한 뒤 30만 부터 50만까지 크롬으로 다시 클리핑했다. 조금이라도 더 빨리 처리할 욕심으로 여러 브라우저를 사용했지만 결과적으로 브라우저가 죽는 바람에 헛 고생만 한 셈이다. 이래서 크롬을 좋아한다.
마지막으로 파폭으로 시도하기 전에 'Internet Explorer 8'로도 클리핑을 시도했었다. 조건은 파폭과 같았다. 그러나 채 만개도 클리핑하지 못하고 뻗어 버렸다. 이런 브라우저를 쓰는 사람이 조금 불쌍하다[3].
- 크롬은 한 서버에 대한 연결을 6개 이상 허용하지 않는다. 따라서 조금이라도 빨리할 욕심에 불여우, 오페라, 사파리등을 이용해서 최대 20개 프로그램을 동시에 돌렸다. 그러나 크롬을 제외하고 끝까지 정상적으로 동작하는 브라우저는 없었다. ↩
- 정치에 관련된 글을 자주 올리기 때문에 더 위험하다. ↩
- 자세한 내용은 크롬, 역시 가장 믿을 수 있는 브라우저를 읽어보기 바란다. ↩
Trackback
Trackback Address :: https://offree.net/trackback/2738
Comments
-
-
Ankh_Isis 2009/09/07 18:22
어익후...이거 클리핑하는게 장난이 아니네요......포기하고 싶은 마음이 샘솟습니다...ㅎㅎ
-
사울아비 2009/09/07 18:46
솔직히 뭔지는 잘 모르지만.. 항상 노력한다는 거 멋진거 같아요..^^ 트위터에서 보고 리플 달러 왔습니다..ㅎ
-
johney 2009/09/08 00:42
도아님 요새 포스팅이 뜸하다 싶었는데, 굉장히 귀찮지만 재밋는 작업을 하고 계셨군요.
아이팟을 사용중하다가 중고로 팔아버렸지만, 다시 장만하게 되면 이용해봐야 겠네요. -
CaN Tips 2009/09/08 07:47
좋은 정보 감사합니다.
저는 동아에서 나온 사전 CD의 데이터베이스를 직접 수정하면서 사용 중인데, 클리핑은 엄두도 못내고 있었습니다. 제 경우 제공해 주신 PHP 파일로는 오류가 나서 잠시 접어두었다가, 아침에 221번 행과 222번 행에서 "/.../is"를 "~...~is"로 변경하여 현재 클리핑을 잘 하고 있는 중입니다. 크롬에 표제어 하나하나가 추가되고 있습니다.
이제 시간과의 싸움이 남았네요.
그리고 국가에서 국민의 세금으로 만든 자료나 보고서 등은 "저작권"이 없어야 맞는 것 같습니다. 국립국어원의 사전 제작 사업도 정확하게 어떤 예산으로 진행되었는지는 모르겠으나, 국민의 세금으로 진행된 것이 아닌가 합니다.
참고로 여느 관공서 사이트와 마찬가지로 우리 청와대 사이트의 경우 하단에 "ALL RIGHTS RESERVED."라는 간단한 문구로 권리를 주장하고 있지만, 미국의 백악관 사이트의 경우 별도로 작성된 페이지에서 "Pursuant to federal law, government-produced materials appearing on this site are not copyright protected."라는 문구를 찾을 수 있습니다. 그냥 습관적으로 쓰는 "ALL RIGHTS RESERVED."라는 문구가 정부 기관, 관공서의 입장에서 수용자인 국민이나 나아가 세계인의 이해와 권익을 생각해볼 필요가 있다고 보여집니다.
클리핑 사례를 통해 저작권에 대한 언급을 하셔서 몇 자 추가해 보았습니다.-
도아 2009/09/08 08:27
이전 글에 있지만 2002년판이 국가예산 112억이 들어간 것입니다. 여기에 7년이니 들어간 예산은 더 많을 것입니다. 따라서 공개가 원칙입니다. 그런데 2009년판은 아예 공개를 안하고 있으니... 조금 그렇더군요.
그리고 동작하는 프로그램이 동작하지 않는다고 해서 확인해 보니 마크다운 포매터가 쓸데없이 EM 태그를 추가해서 발생한 일이더군요. 따라서 본문에 소스를 추가하지 않고 따로 내려받을 수 있도록 했습니다. 제가 보기에 아무래도 다시 클리핑하셔야 할 것같습니다. 클리핑은 되지만 일부 하이라이팅이 먹지 않을 수 있습니다.
-
-
koc/SALM 2009/09/08 09:41
불국사^다보탑의 경우 불국사다보탑보다는 불국사 다보탑으로 해야 더 옳습니다. 표제어에 나타나는 ^(캐럿; Caret) 표시는 "띄어쓰기를 해야 옳지만, 붙여쓰기도 허용한다."라는 뜻입니다.
-
Kael H. 2009/09/08 10:06
도아님은 정말 대단하신 분입니다... ㅇㅅㅇ
전 학교 신종플루 덕에 휴교해서 그저 놀고 있는데...
도아님은 귀중한 일 하나 하셨군요. ㅇㅅㅇ -
koc/SALM 2009/10/23 10:58
[질문]클리핑에 성공한 데이터는 스타딕트 및 그와 호환되는 사전 프로그램에서 사용할 수 있다는 뜻인가요?
** 스타딕(StarDic)의 후속 버전이 스타딕트(StarDict)이더군요. -
wind7129 2009/10/29 15:28
드디어 클리핑 성공했습니다. ^^
$min=1;
$max=2;
테스트로 이렇게 수정해서 돌리니 korea2.txt 가 깔끔하게 만들어지네요..
$min=1;
$max=50000;
$min=50001;
$max=100000;
이렇게 소스를 수정해서 여러개의 ClippingKSD.php 을 만들어 다같이 실행시키는거 맞죠?
감사합니다... -
wind7129 2009/10/31 14:57
컴퓨터 두대로 꼬박 이틀 작업해서 지금 아이팟으로 감동의 눈물을 흘리며 보고 있습니다...
표제어 514502개이네요..
근데 동사같은 경우 null 로 표시되는 단어가 종종 보이네요..
예를 들어 "먹다" 라고 검색하면 (null) (null) 이렇게 뜨네요..
제가 뭘 잘못한건 지 모르겠네요..
그외엔 아주 좋습니다.. 감사합니다.. -
haRu™ 2009/12/09 20:26
생각보다 클리핑이 빡시군요... 30분당 1000개라... 노트북뿐이 없는 저로서는 클리핑이 불가능하겠군요. ㅜ.ㅜ
참 표준국어대사전에 저작권이 세금을 낸 국민이 아니라, 국립국어원에 있군요.
뭐 삼성 핸드폰의 천지인 입력 방식에 특허권이 있다는 사실도 놀랍지만(적어도 삼성 핸드폰의 모음입력 방식의 기본아이디어는 세종대왕이 낸 것인데, 다른 핸드폰회사가 못쓰고 있는 것을 보면...) -
n영만 2009/12/28 20:38
덕분에 많은 도움 얻었습니다 ^^
크롬도 좋지만 브라우저를 이용하는 경우보다 그냥 윈도우용 php.exe 랑 php5.dll 만 가지고 콘솔에서 하는게
시스템에 덜 부담스러운 것같습니다. 메모리도 거의 안먹고 ( 10개 돌렸는데 다합쳐서 메모리 80MB 안넘네요 ^^) -
왕초보인데요 2010/01/07 15:28
도아님의 도움으로 저도 국어사전 말들어가고 있습니다. 감사합니다...
그런데.. 같은 사이트에 맞춤범, 표준어 관련 사전이 있어서.. 이것도 같이 해보려고 하는데요...
어케어케해서 주소는 알아냈는데... 요걸 가지고 어떻게 클리핑할 수 있으런지요...??
소스를 가만히 보니 주소를 적는 부분이 있는 것같아서 흉내 내 보았지만....-_-;;;
결과는 나오지 않네요.... 방법을 알려주실 수 있으신지요...^^;; -
Milea 2010/01/08 09:47
국립국어원의 표제어의 끝이
http://stdweb2.korean.go.kr/search/View.jsp?idx=518129
인듯합니다.
그런데 저 숫자가 가나다 순이 아니더군요?
전부 포함되어있는건가요? -
쏘울 2010/02/20 23:48
좋은 정보 정말 감사드립니다~~다 만들면 완전 대박 사전이 되겠는데요~~
근데 위에보면 재가공해야 한다고 말씀하셨는데 어떻게 해야하나요??
지금 일단은 계속 그냥 돌리고 있는데 완성되고 나면 따로 재가공을 어떡해 해야되죠?? -
방문자입니다 2010/02/23 01:01
도아님의 글을 보고 클리핑을 시도하는 사람입니다. 폐가 되지 않는다면 도아님이 일러두신 범위 안에서 질문을 몇가지 드리고 싶습니다.
첫번째로 크롬호출입니다. 호출이라고 하셨는데 '호출'이라는 것을 좀더 자세하게 설명해 주셨으면 합니다. 콘솔모드에서 작업해봤지만 무슨 이유에선지 클리핑을 하던중 멈춰버리더군요. 오류도 많구요. 아무래도 언급하신 크롬을 사용해야 할것 같아서 입니다.
두번째로 재 가공법입니다. 스타딕 사전파일의 구성을 알고는 있지만 정규식의 장벽에 막혀 재가공을 어떤 부분에서 어떻게 해야하는지 막막합니다. 정규식에 힌트라도 주시면 연구라도 해보겠지만 말이죠... 제가 이제 고등학교를 들어가서 컴퓨터를 만질 시간이 1주일정도 밖에 없는지라(물론 주말은 가능하겠지만..) 입학전에 클리핑을 성공하고 싶네요... -
finesoul 2010/02/24 17:21
도아님의 소개에 따라 몇일을 고생하다가 결국 잘 되었습니다.
중간또 무슨 에라가 발견될지는 모르지만요 ㅎㅎㅎ
몇가지 경험담입니다.
1. 회사네트워크에 방화벽이 내지 보완장비들을 많이 거치면 100개 또는 천개하다가 멈추어 버립니다. 결국 방화벽 밖에서 했습니다.
2. 크롬으로 하다가 포기하고, 검색해서 php5 윈도우 인스톨버전 c:\\php 폴더에 깔고 거기에 도아님소개해 주신 php소스 넣고 결국 명령창에서 c:\\php>php 100000.php 뭐 이런 식으로 콘솔에서 했습니다.
3. 5만개씩 나누어 실행창(cmd) 6개 씩 각각2대를 이용해 2일 동안 실행되었구요 509962개가 모아졌씁니다.
4. 에디터에서 '마름모모양 활용' (php소스를 utp-8로 저장안했나보죠 제가?) 이란 부분이 깨져있는 거 고치고, 고어표시하도록 태그 고치고
5. 에디터에서 찾기에서 http://로 인터넷주소 표시된 부분 남아있는 것 다시 고치고, 그부분 이미지 다시 다운받아넣고 100여개가 있더군요 노가다였습니다. ^^
6. Txt 화일이 완성되면 컴파일 거쳤고 , ifo 화일에 끝에 m을 h로 고쳐주고
7. 이미지는 res 폴더 밑에 넣어 함께 7집으로 묶어 넣고 사전에서 인스톨 설치했습니다. (참고 전 순정폰)
다시 한번 감사드려요 ^^ 친절하게 사용법을 잘 만들어 주셔서요
8. icon_idiom.gif 와 icon_prov.gif 를 추가로 Res 폴더에 다운해서 넣어 주어야 하네요 그래야 속담, 관용이란 아이콘이 차후 사전에서 보이네요
9. 본문안에 정의글 부분에 대한 스타일시트가 php소스에 누락되었는지 없어서 굵게 표기되지 못하네요. .Definition { width:640px} 이부분이 추가되어야 할 것 같습니다. 혹시 차후 하시는 분들 참고하세요 .. T.T 이미 다 클리핑했는데.. 그렇다고 또하는기는 뭐 하네요.. 혹시 다시 클리핑하지 않고 txt 상태의 자료에서 에디터로 수정할 방도가 있으면 알려주세요 -
finesoul 2010/03/10 09:36
도아님 안녕하세요 ^^
위에쓴글 중에서 8번 문제 쪽이 해결된 줄 알았는데 아니네요
도아님의 소개글에는 멋지게 잘 보이는데.. 저는 그렇게 나타나질 않습니다.
혹시나 하고 다시 한 번 여쭈어 봅니다.
'오다' 란 단어를 찾아보면
맨아래 속담 관용어 파트가 있습니다.
이때 속담, 관용 이란 부분은 이미지로 아이콘 처리가
되 있습니다.
Txt 소스에도 이미지는 잘 표현되어 있는데
사전에서 보면 백지상태입니다.
참고로 오다 란 단어 1개로 (표제어 1개죠 ^^) 사전을 만들어
보면 신기하게도 보입니다.
그런데 사전 전체 50만개를 넣고 사전만들어서
찾아보면 사라지네요
어떤 조치를 하면 속담과 관용이란 아이콘이 나타나게 될까요?
1단어만 넣어 보면 보이는 걸 봐서.. 작동은 하는 것 같은데요...
도아님의 노하우 좀 알려주세요 -
-
雨Beer 2010/03/15 03:53
미루고 미루다 출장온김에 저녁에 자기전 걸어두면서 만드는데 성공했습니다. 아무래도 도아님의 정보가 없었으면 만들지 못했을 것 같아 늦었지만 감사의 글을 올립니다.
그나저나 시간은 정말 잡아 먹는 군요 물론 여기 인터넷환경이 안 좋은 점도 있겠지만 그렇지만 결과를 볼 때의 뿌듯함 다시한번 감사합니다. -
스에조 2010/03/17 02:01
도아님 덕분에 좋은 사전을 제작할 수 있었습니다.
프로그램을 공유해 주셔서 고맙습니다.
전 표제어가 514109 나오네요. 중간에 몇번 서버와 연결이 불안정 해서 조금 빠진 것 같습니다.
서버가 너무 자주 끊겨서 txt 파일이 200여개쯤 나오니 다시해볼 엄두는 안나네요.
finesoul님과 다르게 저는 속담 관용이 잘 나옵니다.
아마 res폴더 내에 default.css를 넣어주지 않아서 그런게 아닌가 싶네요.
아이폰이 너무 유용해 졌네요. 다시한번 감사드립니다. -
여우같은고양이 2010/04/10 08:58
도아님의 소스와 강좌 덕에 무지했던 세계를 탐험한 느낌이 듭니다..^^
아직 클리핑중이지만 시작할수 있게 많은 정보 공유해주신거 감사드립니다.. -
야호 2010/08/10 13:29
좋은 자료 감사합니다..
쿠어엉님의 블로그를 통해 이 자료를 보았습니다... 현재 클리핑 중입니다..
도아 님의 자료를 약간 수정을 하여 function 부분을 분리를 하였고, 클리핑이 되지 않은 자료의 번호를 기록하게 하였습니다..
그래서 중지후에 다시 실행을 할때 클리핑이 된 갯수와 에러의 갯수를 합하여 다음 번호부터 클리핑하게 만들었습니다..
에러 파일이 없으니 클리핑한 자료만 보고 재 클리핑 하였더니 중복된 자료가 클리핑이 되어서요...
그리고 오늘 확인을 해보니 국립국어원에 마지막 단어가 518419 이더군요.. 전체를 받은 후 표제어 수가 얼마나 되는지 확인을 해봐야겠습니다... 에러 파일을 이용해 재 클리핑을 해볼까하는데 몇개 test 를 해보면 국어원 사이트에서 없는 것이 더군요.. 클리핑 중 에러나 난 부분은 아닌 듯한데, 확인해보고 올리도록 하겠습니다..
위에 finesoul 님의 9번은 어떤 내용인지 확인 후 수정을 할려고 했는데, 잘 모르겠더군요.. 그래서 일단 그냥 클리핑을 했는데, 좀더 확인을 해보고 에디터에서 수정이 가능한지 확인해야겠습니다.. -
감사 2010/08/27 13:07
일단 클리핑을 완료 하였습니다... 현재 표제어가 510509 이더군요... 사전파일이 너무 커서 컴에 메모리가 부족하여 편집등을 하지 못하고 있네요.... 그런데 데이타는 있는데 몇몇 단어가 나오질 않네요... 어떤 이유인지 찾아봐야 할 듯합니다...
-
규스 2010/09/24 17:37
덕분에 감사히 클리핑 잘 했습니다.
추석 연휴첫날에 했는데 도스창으로 4개를 띄워서 했습니다.
며칠 걸릴 줄 알았는데 멈춤도 없이 아주 잘 되더군요.
클리핑 시간은 10시간도 안걸렸습니다. 어떤분들은 일주일이 걸렸다고 해서 걱정했는데 ㅎㅎ
이미지가 jpg인 것은 잘 제대로 되는거 같은데 gif인 것은 http://~~로 경로가 남아서 수정해줘야하더라구요.
손으로 하나씩 하면 힘드니까 에디터로 [바꾸기]를 이용해서 한번에 바꾸면 편합니다.
한가지 팁이라면 저는 iStardict 쓰는데 폰트 크기설정에 따라서 AppleGothic이랑 nGulim 이 바뀌더라구요. 글씨크기를 116%인가 이하로 설정하면 AppleGothic글씨체로 표현되고(당연 고어는 사각형표시), 117% 이상으로설정하면 nGulim으로 표시됩니다.(고어 이상없이 잘 나옵니다.)
[관용]이랑 [속담] 그림이 안나오는데 나오게 하려면
http://blog.naver.com/seungguk?redirect ··· 91155273 사이트 가셔서 첨부파일에 있는
icon_idiom.gif, icon_prov.gif 의 두개 파일을 꼭 res폴더에 넣어주세요~! -
투로우 2010/09/26 10:27
제가 저 라이브러리를 전에 써봤는데 속도가 굉장히 느립니다
그래서 어쩔 수 없이 직접 file_get_contents로 노가다 처리했더니 속도가 확 줄더군요..
30분에 1000개는 라이브러리 속도때문일거같네요 ^^ -
도일 2010/10/01 14:27
저는 완전히 깡통인가 봅니다...T.T 읽고 읽고 또 읽고 그대로 한 것 같은데도, 도무지 진행이 안되네요...
하도 답답해서, 그냥 글을 올려봅니다.
PHP도 잘 올려져 있고, 샘플 php도 잘 올라오는데, 욽어 오는 건 그냥 하얀 화면 그대로네요....
도스 화면에서 시도하는 방법을 해 봐도 연결 끊김만 자꾸 반복되고....포기할까봐요...흐흐흐 -
라이도스 2010/10/09 20:59
클리핑한 파일을 사전에 넣어봤습니다..
사전에 제목하고 그림은 제대로 나오는데
정작 단어에 대한 설명이 빠진게 많네요....
뭐가 부족한걸까요?
클리핑된 파일을 직접 열어봤는데 정상적인 단어들은 태그가 쭉 있고 뒤에 설명이 있습니다..
그런데 몇몇 단어는 발음, 품사명 까지만 있고 뒤에 아무리 찾아봐도 설명이 없습니다...
(몇몇 단어라고 표현했지만 반정도가 설명이 빠져있습니다..)
제가 이런쪽은 잘 몰라서 최대한 자세히 적었는데 정확히 질문을 했는지 모르겠네요...
아... 지금 적다가 확인한건데 사진파일은 인터넷에 연결되있는 상태에서만 보이네요....
클리핑할때 사진파일은 따로 안생겼는데 이거만 따로 빼는 방법있나요?
이상한 질문만 잔뜩해서 죄송합니다... -
잘배우고 갑니다.. 2010/10/15 17:23
도아님 소스로 클리핑 했습니다..
저는 클리핑하는데 한 5시간정도 걸린듯하네요..
국립국어원 사이트가 빨라진건지 영한영할때보다 몇배는 빨리끝난듯..
단한가지 문제가 있다면 관용구/속담부분 이미지가 안나온다는점..
이건 좀더 수정을 해봐야될듯하네요..
소스 감사드립니다~^^ -
sniper 2011/03/20 02:39
1만개 단위로 끊어서 52개를 도스로 클리핑 결과 509900,
도아님보다 540개가 부족한 숫자로 클리핑 완료 됐네요.
기다리기 힘드신분은 이 방법을 추천합니다.
540개 날리고 5시간이면 클리핑 완료네요... -
-
-
도아 2012/10/05 09:51
하나의 댓글로 달면 되는 글을 두개의 댓글로 달면 도배로 차단됩니다. 아울러 저는 비밀 댓글에는 답하지 않습니다. 댓글 달기 전에 최소한 댓글 입력창 옆에 있는 비밀글로 질문하지 않았으면 합니다.라는 글 정도는 읽고 댓글 달기 바랍니다.
-
-
노래하는다롱이 2019/08/18 18:44
업데이트 겸 다시 만들려고 하니 국립국어원의 표준국어대사전 웹페이지가 많이 바뀌었습니다. 그래서 예전 스크립트를 사용할 수가 없어서 아쉽습니다. 혹시 클리핑 스크립트를 업데이트하실 의향은 없으신가 해서 들러봤습니다. 건강하세요.
Facebook