NOARCHIVE를 지키지 않는 네이버
 과연 네이버는 엠파스를 비난할 자격이 있을까? 펌로거를 이용해서 인터넷의 거의 모든 자료를 퍼오록 하고 robots.txt(검색 엔진 배제표준)을 이용해서 다른 검색 엔진 봇의 접근을 막는 비양심적인 행동도 네이버의 태생적 한계로 보자. 이렇다고 처도 과연 "네이버는 엠파스를 비난할 자격이 있을까?" 결론부터 이야기 하면, 없다
과연 네이버는 엠파스를 비난할 자격이 있을까? 펌로거를 이용해서 인터넷의 거의 모든 자료를 퍼오록 하고 robots.txt(검색 엔진 배제표준)을 이용해서 다른 검색 엔진 봇의 접근을 막는 비양심적인 행동도 네이버의 태생적 한계로 보자. 이렇다고 처도 과연 "네이버는 엠파스를 비난할 자격이 있을까?" 결론부터 이야기 하면, 없다
꽤 오래 전의 일이다. 이제는 사라진 엠파스에서 열린 검색을 들고 나올 때이다. 이때 네이버는 엠파스가 검색 엔진 배제표준(Robots Exclusion Protocol)을 지키지 않는다고 비난했다. 그도 그럴 것이 네이버는 자사의 컨텐츠를 보호한다는 미명하에 모든 봇이 네이버에 접속할 수 없도록 설정했기 때문이다. 따라서 엠파스의 봇이 검색 엔진 배제표준을 지켰다면 엠파스가 열린 검색을 통해 네이버의 컨텐츠를 검색할 수 없어야 정상이기 때문이다.
NOARCHIVE를 지키지 않는 네이버
그러면 과연 네이버는 엠파스를 비난할 자격이 있을까? 펌로거를 이용해서 인터넷의 거의 모든 자료를 퍼오록 하고 robots.txt(검색 엔진 배제표준)을 이용해서 다른 검색 엔진 봇의 접근을 막는 비양심적인 행동도 네이버의 태생적 한계로 보자. 이렇다고 처도 과연 네이버는 엠파스를 비난할 자격이 있을까? 결론부터 이야기 하면,
없다
블로그에는 날라간 글이 몇개 있다. 글이 날라가게된 동기는 텍스트큐브의 자동 저장 기능 때문이었다. 글을 쓰면서 이전 글을 인용하기 위해 여러 개의 수정창을 열었다. 그리고 실수로 엉뚱한 창에 새글을 복사했는데 텍스트큐브가 이 글을 자동으로 저장했기 때문이다. 어제도 비슷한 일이 발생했다. 다만 이번에는 자동 저장을 한 것이 아니라 글의 제목을 확인하지 않고 저장했기 때문에 발생한 일이다. 어제 한울 배추 김치에 대한 글을 쓰면서 이전에 작성한 한울 김치에 대한 글, 김치와 천일염의 비밀에 붙여넣고 저장 단추를 눌렀다.
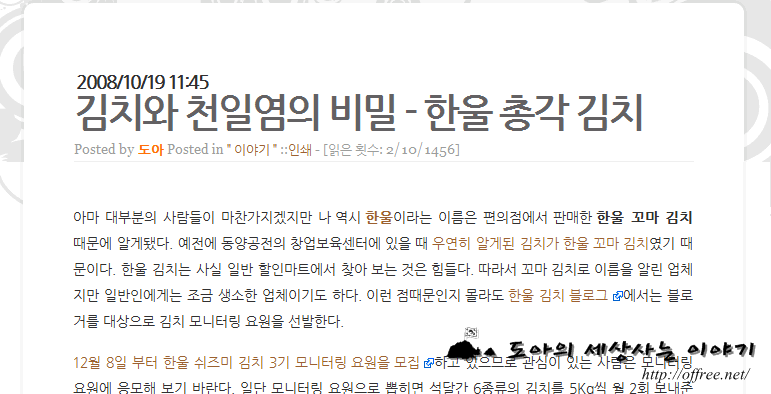 사라진 김치와 천일염의 비밀
사라진 김치와 천일염의 비밀
사용하고 있는 웹 브라우저가 Internet Explorer였다면 캐시를 뒤지면 나왔겠지만 크롬이다 보니 캐시를 뒤져도 글이 남아 있지 않았다. 이경우 다른 사람들은 잃어버린 데이타를 복구할 수 있는 쉬운 방법이 있다. 바로 구글의 저장된 페이지과 같은 웨이백 시스템을 이용하는 것이다.
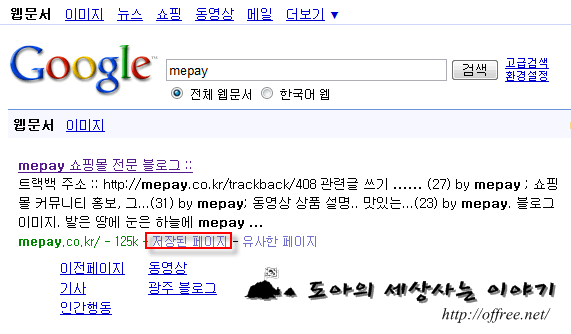 구글에서 제공하는 웨이백 시스템
구글에서 제공하는 웨이백 시스템
검색 결과 아래쪽에 저장된 페이지를 클릭하면 구글 서버에 저장되어 있는 저장된 페이지를 확인할 수 있다.
그러나 이 블로그는 명예훼손등의 이유로 웨이백 시스템에 글 자체를 남기지 않는다. 더러운 천민자본주의와 명예훼손라는 글에서 설명한 것처럼 웨이백 시스템에 캐시된 데이타를 남기지 않으려면 <HEAD>와 </HEAD> 태그 사이에 다음과 같은 <META>태그를 넣으면 된다.
<meta name="robots" content="noarchive">
<meta name="googlebot" content="noarchive">
따라서 현재 운영하고 있는 QAOS.com이나 도아의 세상사는 이야기는 구글 캐시에도 그 데이타가 남아 있지 않다. 또 Archive.org과 같은 웨이백 시스템에도 역시 남아 있지 않다. 라이브 검색, 야후 검색등 웨이백 시스템을 제공하는 모든 시스템에서도 찾을 수 없도록 하고 있다.

mepay님의 블로그와는 달리 '도아의 세상사는 이야기'에는 저장된 페이지라는 링크가 없다. 캐시하지 않도록 하고 있기 때문이다. 다만 이 블로그는 구글 뿐 아니라 모든 검색 엔진에서 캐시하는 것을 막고 있다.
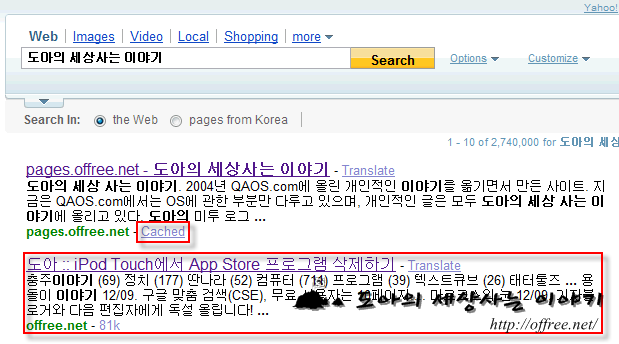
야후도 마찬가지다. <pages.offree.net>은 'Cached' 링크가 있지만 offree.net에는 이 링크가 존재하지 않는다. pages.offree.net은 구글 앱스를 이용해서 현재 운영하고 있는 사이트를 소개한 페이지 이기 때문에 캐시된 것 뿐이다.
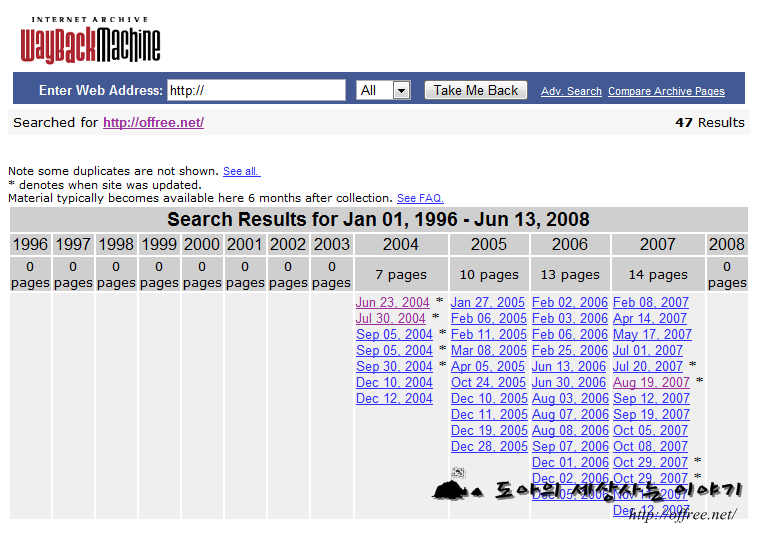
대표적인 웨이백머신인 Archive.org에도 2007년까지의 데이만 캐시되어 있는 것을 알 수 있다. 저작권이나 다른 문제가 발생할 수 있기 때문에 Archive.org에도 캐시하지 않는다.
따라서 이렇게 글을 날리면 복구할 수 있는 유일한 방법이 웹 호스팅 업체의 백업된 DB이다. 결국 웹 호스팅 업체에 연락해서 백업된 DB를 보내 줄것을 요청했다. 백업된 DB를 받았지만 확인해 보니 이 DB에는 2008년 8월 29일까지의 데이타만 남아있었다. 웹 호스팅 업체에 연락해서 확인해 보니 백업 서버의 하드 디스크 용량이 꽉찬덕에 8월 29일 이후로는 DB 백업이 이루어지지 않았다는 것이다.
똥 묻은 네이버 겨 묻은 엠파스 나무라기
글 하나가 뭐가 중요할까 싶지만 글 하나에 들이는 정성을 생각하면 하나의 글도 소중하다. 그래서 사라진 글을 복구할 수 있는 방법을 생각하다가 네이버가 떠 올랐다. 다른 검색 엔진이 NOARCHIVE를 준수한다고 해도 인터넷의 퍼진 자료를 자사의 DB로 퍼오는 것에만 신경쓰는 네이버라면 캐시에 내 글이 남아 있지않을까 하는 생각이 든 것이다. 네이버가 다른 검색 엔진처럼 도덕적이라면 절대 있을 수 없는 일이다. 그러나 지금까지 보여준 네이버의 모습 보면 이 역시 지키지 않을 것으로 생각했다.
따라서 네이버에서 사라진 글을 검색했다. 사라진 글은 "김치와 천일염의 비밀"이지만 네이버 검색에서는 구단위의 검색이 되지 않기 때문에 김치 천일염 비밀로 검색했다. 그리고 저장된 페이지를 클릭했다.
있었다.
역시 네이버 답다. 저장하지 말라고 메타태그에 NOARCHIVE를 지정했지만 천연덕스럽게 자사의 DB에 저장하고 있었다.
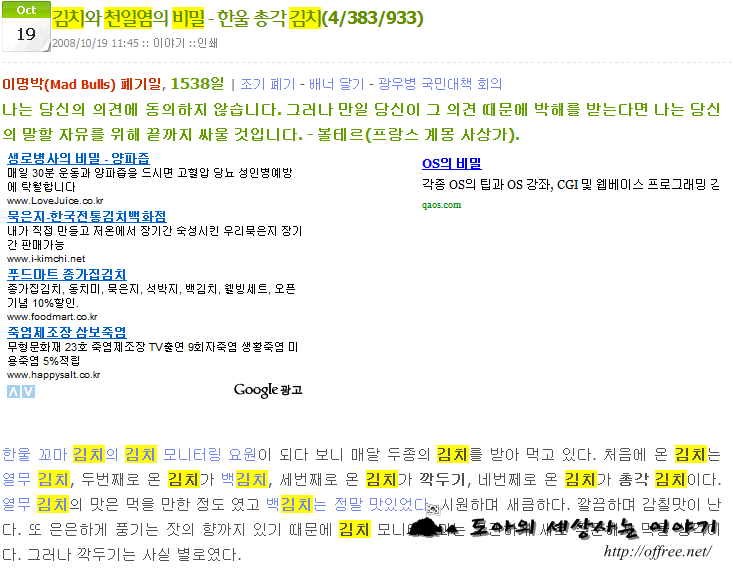
 역시 생각대로 T*내는 네이버
역시 생각대로 T*내는 네이버
역시 생각대로 남아있었다. 이 캐시에 저장된 데이타를 이용해서 날라간 데이타를 복구하는데 성공했다. 혹시 NOARCHIVE가 없는 문서를 캐시한 것인지 확인하기 위해 소스 보기로 확인해 봤다. 그림에서 알 수 있지만 NOARCHIVE가 아주 선명하게 남아 있다.
다른 모든 검색 엔진이 준수하는 규칙을 네이버는 지키지 않는다. 그러면서 다른 검색 엔진이 검색 엔진 배제표준을 지키지 않았다고 비난한다. 네이버를 비판하는 사람은 정말 많다. 그런데 문제는 네이버는 이런 비판을 색안경으로 본다는 점이다. 아울러 이런 비판에 네이버는 귀기울일 생각을 하지 않는다. 네이버 직원이 쓴 글을 보면 다음과 같은 글귀가 나온다.
모든 일에는 편견이 존재한다. -> "맞다."
네이버에도 편견이 존재한다. -> "맞다."
네이버를 심하게 비판하는 사람은 심한 편견을 가지고 있다.->"왜 그렇게 생각하는데?"
내가 보기에 그렇다. -> "자기가 그렇게 생각하는 것이 논리의 기준?"
"네이버를 심하게 비판하는 사람은 아주 심한 편견을 가지고 있다"고 하면서 정작 무엇이 왜 색안경인지는 전혀 이야기 하지 않고있다[참조: 점프컷]. 더 큰 문제는 이런 논리의 기반이 자신의 생각뿐이라고 한다. 명백히 다른 검색 엔진에서 지키고 있는 것을 네이버는 지키지 않는다. 그러면서 다른 검색 엔진은 이런 규칙을 지키지 않는다고 비난한다.
과연 이 것이 색안경일까?
똥묻은 개가 겨묻은 개를 나무란다는 속담이 있다. 다른 사람의 얼굴에 묻은 겨를 탓하고 싶다면 먼저 자신의 얼굴에 묻은 똥부터 닦아 내는 것이 순서다. 이 것이 기본이다. 네이버의 문제는 이런 기본조차 모른다는 것이다.
 마지막 짤방
마지막 짤방
저장하지 않도록 NOARCHIVE를 써도 글을 저장하면서 페이지 가장 윗쪽에는 내용에 책임을 지지 않는다는 것과 웹문서 삭제 요청 방법에 대한 도움말을 링크하고 있다. 역시 네이버스럽다고 해야 할까?
남은 이야기
네이버에서 받은 도움
이 글을 보는 사람 중 네이버에서 실질적인 도움(글의 복구)을 받았으면서 네이버를 깐다고 욕하는 사람이 있을 수 있다. 그러나 중요한 것이 하나있다. 도움을 받은 것과 부당한 것은 서로 다른 문제라는 점이다. 즉 도움을 받았다고 부당한 것이 정당한 것이 되지는 못한다. 네이버는 국내 최대의 포털이다. 네이버라는 병리현상라는 글에서 설명한 것처럼 우리사회는 네이버라는 병리현상에 병들고 있다.
이런 권력을 가진 네이버가 그 권력을 오용하면 사회에 미치는 파장은 정말 커진다. 모든 웨이백 머신에 캐시하지 않도록 했기 때문에 어느 정도 명예훼손에 대항할 수 있는 방법이 있다. 그런데 네이버의 현 시스템은 이런 저작권자의 노력을 한순간에 물거품으로 만들어 버린다. 이 문제는 단순히 네이버의 문제가 아니다. 실제 저작권자에게 치명적인 피해를 줄 수 있는 문제다. 또 많은 사람들이 지속적으로 네이버의 저작권 방조 혐의를 이야기한다. 그 이유는 네이버의 이런 시스템 때문이다.
구글 검색 엔진의 저작권 정책
네이버가 하면 모두 악이고 구글이 하면 모두 선인가?
한 네이버 직원의 말이다. 이 말의 정답은 간단하다. '아니다'. 이런 것을 묻는 수준을 묻고 싶지만 이 말에 "예"라고 답할 사람은 사실없다. 이 말은 다음처럼 고처져야 한다.
'네이버가 하면 대부분 악이고 구글이 하면 대부분 선인가?'
이 말의 정답은 '예'이다. 그 이유는 간단하다. 저작권을 바라보는 시각 자체가 다르기 때문이다. 다음은 저작권 및 웹 검색에 관한 구글의 정책이라는 글에 나온 내용이다. 구글이 하면 대부분 선인 이유는 구글은 저작권자의 의견을 존중해 주기 때문이다.
웹 퍼블리셔의 의견을 존중할 수 있는 이유는 구글이 '인터넷 검색 엔진 배제표준'(Robots Exclusion Protocol)과 NOARCHIVE 메타 태그를 준수하기 때문입니다. 구글보다 앞서 잘 정립된 기술에는 검색 엔진에 사이트의 어떤 부분이 검색 가능하고, 어떤 부분은 검색결과에 나타나야 할지를 구별하는 기능이 있습니다.
네이버의 로봇 정책 변경
네티즌에 의해 수없이 많은 비판을 받았던 네이버의 로봇 정책은 2006년 6월경 바뀌었다. 따라서 이제는 구글을 통해서도 네이버가 검색된다. 그러나 네이버 시스템의 복잡한 구조탓인지 실제 다른 검색 엔진을 통해 네이버의 컨텐츠를 검색하는 것은 아주 힘들다. 또 네이버를 이용해서 검색해도 찾기 힘들다(자체 DB를 검색하는 능력도 떨어지는 듯하다).