표준국어대사전
 국립국어원의 표준국어대사전 2002년판은 동아출판사에서 사전으로 배포했다. 그러나 최근에 완성된 표준국어대사전은 이렇게 배포하지 않고 있다. 오로지 표준국어대사전 사이트를 통해서만 사전을 사용할 수 있다. 물론 PC에 설치해서 사용할 수 있는 프로그램도 있다. 그러나 이 프로그램도 표준국어대사전 사이트를 검색한 결과를 되돌려 주는 것에 불과하다. 따라서 표준국어대사전을 딕셔너리 유니버샬에서 사용할 수 있는 사전 파일로 만들기 위해서는 클리핑(Clipping) 작업이 필수적이다.
국립국어원의 표준국어대사전 2002년판은 동아출판사에서 사전으로 배포했다. 그러나 최근에 완성된 표준국어대사전은 이렇게 배포하지 않고 있다. 오로지 표준국어대사전 사이트를 통해서만 사전을 사용할 수 있다. 물론 PC에 설치해서 사용할 수 있는 프로그램도 있다. 그러나 이 프로그램도 표준국어대사전 사이트를 검색한 결과를 되돌려 주는 것에 불과하다. 따라서 표준국어대사전을 딕셔너리 유니버샬에서 사용할 수 있는 사전 파일로 만들기 위해서는 클리핑(Clipping) 작업이 필수적이다.
목차
사전 만들기
- iPod Touch 강좌 51. 사전 만들기 1. 소개 국립국어원의 표준국어대사전은 표제어의 수가 50... 새창
- iPod Touch 강좌 55. 사전 만들기 3. 컴파일 이번에는 사전 만들기의 세번째 강좌로 클리핑된 ... 새창
- iPod Touch 강좌 56. 사전 만들기 4. 설치 아이팟 터치(iPod Touch)를 사용하면서 사전 어플... 새창
- iPod Touch 강좌 57. 사전 만들기 5. 옛... 이번 글은 사전 만들기의 마지막 강좌이다. 사전... 새창
클리핑
아이팟 터치(iPod Touch)용 표준국어대사전 기능은 이전 강좌에서 소개했다. 따라서 이 글에서는 사전에 대한 간단한 소개와 클리핑하는 방법을 이야기하겠다. '아이팟 터치'용 표준국어대사전은 이미지를 지원하며 표제어가 51'0440개인 아주 방대한 사전이다. 웹 데이타를 그대로 따왔기 때문에 아이팟 터치용 사전 치고는 예쁘며 파일 크기가 상당히 크다. 이미지를 포함한 사전 파일은 총 566M에 달한다. 사전에 이미지를 포함하고 있기 때문에 weDict에서는 사용할 수 없고 오로지 딕셔너리 유니버샬(Dictionary Universal)에서만 사용할 수 있다.
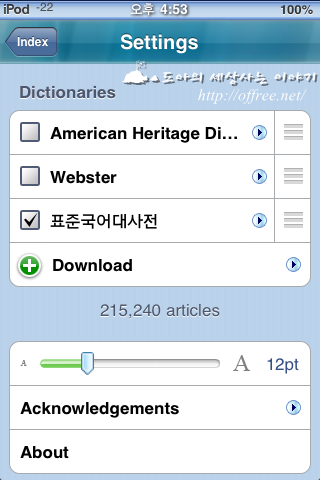
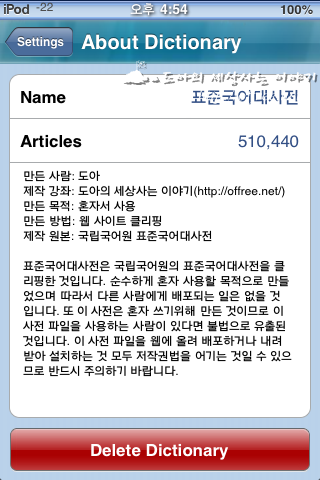


먼저 가장 왼쪽의 그림은 딕셔너리 유니버셜에 등록되어 있는 사전들이다. 두번째 그림은 표준국어대사전에 대한 간단한 정보이다. 표제어의 수는 스타딕 사전 파일을 만들면 자동으로 추가된다. 사전 이름과 설명은 정보 파일을 직접 편집해서 추가한 것이다. 표준국어대사전을 클리핑하다 보면 재미있는 단어들이 많았다.
먼저 행사다. 행사는 우리말로는 '어떤 일을 시행함. 또는 그 일.'이라고 정의돠어 있지만 북한말로는 '국가나 사회단체 따위가 일정한 계기와 목적 밑에 특별히 조직하는 대중 정치사상 사업의 하나', '기껏하여 한다는 일이나 짓.'이라고 한다. 행정편의주의 때문에 갖은 전시행사가 열리는 우리나라에서 보면 우리말 정의 보다는 북한말 정의가 더 가슴에 와닿는다. 또 사전을 만들다 보니 후장총이라는 단어도 있었다. '후장'이 가지는 비속어 이미지가 있기 때문에 이 단어 자체가 조금은 우수웠다. 아무튼 완성된 사전의 파일의 정보는 다음과 같다.
| 파일 | 크기 | 설명 |
|---|---|---|
| KSD2009.dict | 408,417,612 | 사전 정보를 담고 있는 메인 사전 파일 |
| KSD2009.idx | 9899794 | 표제어 색인을 담고 있는 인덱스 파일 |
| KSD2009.ifo | 985 | 사전 설명과 사전에 대한 정보를 담고 있는 정보 파일 |
| res | 177,011,084 | 총 9189개 이미지를 저장하고 있는 이미지 폴더 |
| KSD2009.tar.bz2 | 197,218,769 | 스타딕 배포본 형태로 압축한 파일 |
표준국어대사전
국립국어원의 표준국어대사전 2002년판은 동아출판사에서 사전으로 배포했다. 그러나 최근 완성된 표준국어대사전은 이렇게 배포하지 않고 있다. 오로지 표준국어대사전 사이트를 통해서만 사전을 사용할 수 있다. 물론 PC에 설치해서 사용할 수 있는 프로그램도 있지만 이 프로그램도 표준국어대사전 사이트를 검색한 결과를 되돌려 주는 것에 불과하다. 따라서 표준국어대사전을 딕셔너리 유니버샬에서 사용할 수 있는 사전 파일로 만들기 위해서는 클리핑(Clipping) 작업이 필수적이다.
표준국어대사전의 클리핑 주소는 http://stdweb2.korean.go.kr/search/View.jsp?idx=1로서 'idx'의 값을 1에서 518063까지 바꾸면 '총 510440개 표제어'를 클리핑할 수 있다. 또 클리핑을 하다 보면 중간에 빠지는 주소가 종종 나타난다. 과거에 표준국어대사전에 등록했지만 표준이라는 말에 걸맞지 않아 삭제한 것으로 보인다. 이렇게 빠진 데이타는 다음과 같다. 5만개 단위로 클리핑했기 때문에 5만개 단위로 빠진 인덱스를 추가했다.
| 순번 | 범위 | 순번 | 범위 |
|---|---|---|---|
| 50000 | 50000-887=49113 | 350000 | 50000-634=49366 |
| 100000 | 50000-798=49202 | 400000 | 50000-780=49220 |
| 150000 | 50000-734=49266 | 450000 | 50000-659=49341 |
| 200000 | 50000-697=49303 | 500000 | 50000-596=49404 |
| 250000 | 50000-738=49262 | 518063 | 18063-405=17658 |
| 300000 | 50000-695=49305 | 총 | 518063-7623=510440 |
클리핑 방법
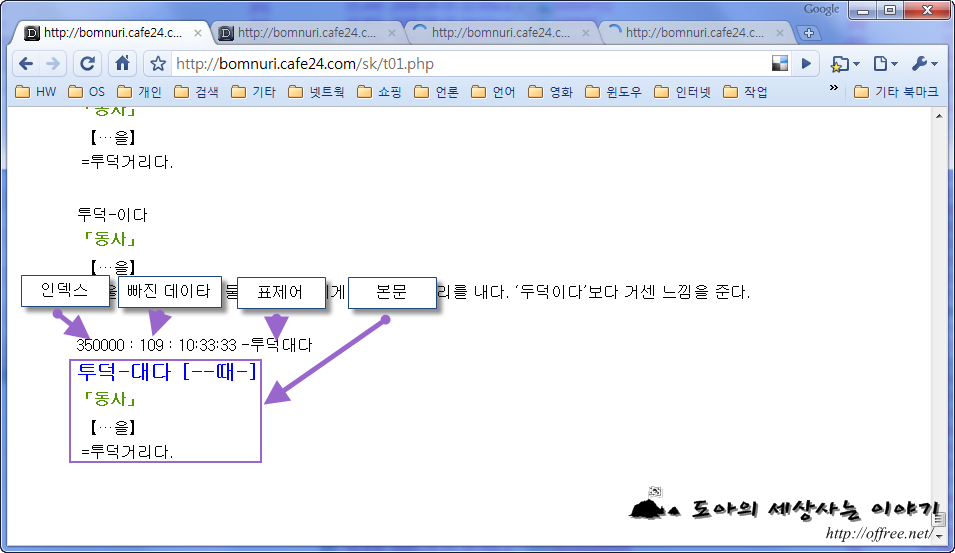
클리핑하는 방법은 간단하다. 다음 그림은 표준국어대사전에서 불국사 페이지를 인덱스로 연 뒤 소스 보기를 한 것이다.

① ①에서 ^를 제거한 뒤 표제어로 사용한다.
② ①과 ②를 합쳐서 사전 페이지의 제목으로 사용한다.
③ ③은 설명으로 사용한다. 다만 이렇게 하면 웹 페이지처럼 표시되지 않기 때문에 'class' 속성 대신에 'style' 속성으로 바꿔야 한다.
④ ④는 이미지이다. 이 주소를 그대로 사용해도 되지만 인터넷 연결이 끊기면 그림이 표시되지 않는다. 따라서 이 부분은 filename.jpg로 바꾸고 사전 폴더에 'res'라는 하위 폴더를 만들고 이 폴더에 filename.jpg를 넣어두면 딕셔너리 유니버샬(Dictionary Universal)이 알아서 이미지를 가져온다.
이렇게 클리핑한 데이타를 표제어, 탭, 설명순으로 두면 사전 파일의 한 행이 만들어 진다.
불국사다보탑 <div style='font-weight: bold; font-size: 20px; color: #0000ff; font-family: AppleGothic, nGulim;'>불국사^다보탑(佛國寺多寶塔)</div><span style="font-family:tahoma; font-weight:bold;color:#549606; padding-top:-10px; margin-bottom:-0.1;vertical-align:top">「고적」</span><br><ul style="font-family:AppleGothic, Sans-serif;color:#000000; line-height:1.5; padding:5px;list-style: none;"><li><span style="width:45px; font-weight:bold;color:#cb4a00;vertical-align:top; text-align:right"> </span>경주 불국사 경내에 있는 대웅전 앞에 있는 두 탑 중 동쪽에 있는 탑. 통일 신라 경덕왕 10년(751)에 건립된 것으로 추정된다. 높이는 10.4미터 정도이며 화강암으로 되어 있다. 국보 제20호. ≒다보탑「1」. <br></li></ul><center><img src='fd009sz.jpg' width='300'><br></center>
여기서 'font-family'에서 'AppleGothic' 다음에 'nGulim'을 추가한 이유는 nGulim이 고어를 지원하기 때문이다. 즉, 일반문자는 AppleGothic으로 표시하고 고어는 nGulim으로 표시하게 된다. 이런 작업을 idx 1부터 518063까지 하면 된다. 사전 파일에 한글이 포함되면 반드시 파일을 UTF-8로 저장(dict, ifo 모두 해당)해야 한다. 그렇지 않으면 글자가 깨지거나 잘못된 사전 파일로 뜬다. 당연한 이야기지만 이 작업은 수작업으로 할 수는 없다. 따라서 주변에 프로그램을 짤 줄 아는 사람이 있다면 부탁하는 것이 좋다.
클리핑 어플
나는 PHP로 간단한 클리핑 프로그램을 짠 뒤 한번에 5만개씩 가져오도록 했다. 1000개의 데이타를 30분에 가져오기 때문에 52만개를 가져오려고 하면 총 10일 20시간이 걸린다. 이런 문제 때문에 총 6개의 프로그램을 돌려 이틀 동안 클리핑했다. 이 과정에서 프로그램 오류, 브라우저 오류로 약 100만개의 크리핑 데이타1를 날렸다. 즉, 프로그램을 이용해도 쉬운 작업은 아니었다.
프로그램을 짤 줄 모르고 주변에 아는 프로그래머도 없다면 내가 짠 프로그램을 사용해도 된다. 단순히 클리핑을 위해 짠 프로그램이라 소스를 이해하기 조금 힘들 수 있다. 다만 주의할 것은 '이 프로그램에 대한 어떠한 질문도 받지 않는다'는 점이다. 따라서 자기 호스팅 서버에 이 프로그램을 돌려보고 동작하면 웃고 그렇지 않으면 지우면 된다. 아울러 이 프로그램에 대한 질문이 올라오면 답하지 않고 바로 삭제할 생각이다.
프로그램 받기: ClippingKSD.php
<?php
//
// 국립국어원 표준국어대사전 클리핑 프로그램
//
// 이 프로그램은 누구나 수정할 수 있지만 배포는 금지합니다.
// 이 프로그램에 대한 어떠한 질문도 받지 않습니다.
// 따라서 이 프로그램을 실행해서 잘 동작하면 웃고, 그렇지 않으면 이 프로그램을 바로 지우기 바랍니다.
//
// 판올림도 없고 버그 수정도 없습니다.
// 이 프로그램을 사용함으로 발생하는 모든 책임은 본인 스스로에게 있습니다.
//
// $min, $max로 클리핑 범위를 지정
// 프로그램과 같은 폴더에 korea.불max.txt 형태의 파일로 데이타가 클리핑됨
// 이미지가 있으면 자동으로 이미지를 내려받음
// 이미지 뿐만 아니라 본문에 포함된 한자, 고어, 수식등 모든 이미지를 처리
//
set_time_limit(0);
include_once('simple_html_dom.php');
$min=1;
$max=518063;
//
function getQuery($host_ip, $port, $query) {
global $nuke_url;
$hostname = ereg_replace("^http://([^/]*)[/]*", "\\1", $nuke_url);
$referer = "http://".불_SERVER["HTTP_HOST"].불_SERVER["REQUEST_URI"];
$fp = @fsockopen($host_ip, $port, &$errno, &$errstr, 10);
if(!$fp) {
echo "$errstr: $errno \n";
}else {
@fwrite($fp, "GET $query HTTP/1.0\r\nHost: $hostname\r\nUser-Agent: DoA/1.1\nReferer: $referer\nConnection: Close\r\n\r\n");
while(!@feof($fp)) {
$list .= @fgets($fp, 1024);
}
}
@fclose($fp);
//
list($header, $body) = preg_split("/\r\n\r\n/", $list, 2);
return $body;
}
//
function getDict($str_html) {
$str_html = str_replace('‘<’', '‘<’',$str_html);
$str_html = str_replace('‘>’', '‘>’',$str_html);
$str_html = strip_tags($str_html, '<div><ul><li><img><span><td> ');
$pattern=array('sword', 'provtitle','exp', 'sdblue', 'NumRG', 'NumRG2', 'NumNO', 'Use_icon', 'idiom_list', 'prov', 'idiom');
$replace=array(
'font-family:AppleGothic, Sans-serif ; font-size:14px; font-weight:bold; color:#336699',
'',
'font-family:AppleGothic, Sans-serif;color:#000000; line-height:1.5; padding:5px;list-style: none;',
'font-family:AppleGothic, Sans-serif; font-size:13px;color:#336699;',
'font-family:tahoma; font-weight:bold;color:#549606; padding-top:-10px; margin-bottom:-0.1;vertical-align:top',
'font-family:tahoma; font-weight:bold;color:#336699;padding-left:8px; margin-top:-10;vertical-align:top;',
'width:45px; font-weight:bold;color:#cb4a00;vertical-align:top; text-align:right',
'color:#444444; padding-left:20px;font-size: 13px',
'list-style: none;padding:5px;',
'background:url(icon_prov.gif) no-repeat; background-position:0px 5px; padding:5px 0px 5px 30px;line-height:1.3',
'background:url(icon_idiom.gif) no-repeat;background-position:0px 5px; padding:5px 0px 5px 30px; line-height:1.3');
$str_html = str_replace($pattern, $replace, $str_html);
$html= str_get_html($str_html);
//
foreach($html->find('span[id=print_area]') as $article) {
//
$item['title1'] = trim($article->find('span.word_title', 0)->plaintext);
$pattern = array("^", "-", "0", "1", "2", "3", "4", "5", "6", "7", "8", "9");
$replace = array('', '', '', '', '', '', '', '', '', '', '', '', '', '');
$item['title1'] = str_replace($pattern, $replace, $item['title1']);
$item['title2'] = trim($article->find('td.pb10', 0)->plaintext);
$item['use']=trim($article->find('td[id=use_title]', 0)->plaintext);
$pattern = array("\r\n", "\n", "\r", "\t", " ");
$replace = array('', '', '', '', '');
$item['title2'] = str_replace($pattern, $replace, $item['title2']);
$item['use'] = str_replace($pattern, $replace, $item['use']);
list($temp, $item['use'])=split(':', $item['use']);
$item['list1'] = trim($article->find('div.list', 0)->innertext);
if($article->find('div.list2', 0)) {
$item['list1'] .= " ".trim($article->find('div.list2', 0)->innertext);
$diff++;
}
if($article->find('div.list2', 1)) {
$item['list1'] .= " ".trim($article->find('div.list2', 1)->innertext);
$diff++;
}
//
$pattern = array("\r\n", "\n", "\r", "\t");
$replace = array('', '', '', '');
$item['list1'] = str_replace($pattern, $replace, $item['list1']);
$item['list2'] = trim($article->find('div', 1+$diff)->innertext);
$item['list2'] = str_replace($pattern, $replace, $item['list2']);
$item['list3'] = trim($article->find('div', 2+$diff)->innertext);
$item['list3'] = str_replace($pattern, $replace, $item['list3']);
$item['list4'] = trim($article->find('div', 3+$diff)->innertext);
$item['list4'] = str_replace($pattern, $replace, $item['list4']);
$item['list5'] = trim($article->find('div', 4+$diff)->innertext);
$item['list5'] = str_replace($pattern, $replace, $item['list5']);
$item['list6'] = trim($article->find('div', 5+$diff)->innertext);
$item['list6'] = str_replace($pattern, $replace, $item['list6']);
}
//
$html->clear();
unset($html);
return $item;
}
//
function getHtml($num) {
$query = '/search/View.jsp?idx='.불num;
$str_html = getQuery('stdweb2.korean.go.kr', 80, $query);
return $str_html;
}
//
function saveImg($url) {
$host=parse_url($url);
$img = getQuery($host['host'], 80, $host['path']);
$file=split('/', $host['path']);
$filename=array_pop($file);
$fp=fopen($filename, 'w');
fwrite($fp, $img);
fclose($fp);
return $filename;
}
//
function getImgInfo($img) {
$html= str_get_html($img);
$url=$html->find('img', 0)->src;
$alt=$html->find('img', 0)->alt;
return array($url, $alt);
}
//
function saveDict($filename, $cont) {
$fp=fopen($filename, 'a');
fwrite($fp, $cont);
fclose($fp);
}
//
header("Content-Type: text/html; charset=utf-8");
//
for($i=$min; $i <= $max; $i++) {
$str_html=getHtml($i);
$dict=getDict($str_html);
//
if($dict['img']!='') {
$dict['img']=saveImg($dict['img']);
}
//
if($dict['title1']=='') {
$count++;
continue;
}
$saveDict = $dict['title1']."\t<div style='font-weight: bold; font-size: 20px; color: #0000ff'>".불dict['title2']."</div>";
if($dict['use']!='') $saveDict .= " <b>◈ 활용</b>:".불dict['use']." ";
//
if($dict['list1']!=''){
if(preg_match("/<img.*/",$dict['list1'])) {
list($url, $alt) = getImgInfo($dict['list1']);
$filename=saveImg($url);
if(preg_match("/.gif/is", $filename)) {
$dict['list1']=str_replace($url, ""$filename"", $dict['list1']);
$saveDict .= $dict['list1'];
}else $saveDict .= "<center><img src='".불filename."' width='300'> ".불alt."</center>";
}else $saveDict .= $dict['list1'];
}
//
if($dict['list2']!=''){
if(preg_match("/<img.*/",$dict['list2'])) {
list($url, $alt) = getImgInfo($dict['list2']);
$filename=saveImg($url);
if(preg_match("/.gif/is", $filename)) {
$dict['list2']=str_replace($url, ""$filename"", $dict['list2']);
$saveDict .= $dict['list2'];
}else $saveDict .= "<center><img src='".불filename."' width='300'> ".불alt."</center>";
}else $saveDict .= " ".불dict['list2'];
}
//
if($dict['list3']!=''){
if(preg_match("/<img.*/",$dict['list3'])) {
list($url, $alt) = getImgInfo($dict['list3']);
$filename=saveImg($url);
if(preg_match("/.gif/is", $filename)) {
$dict['list3']=str_replace($url, ""$filename"", $dict['list3']);
$saveDict .= $dict['list3'];
}else $saveDict .= "<center><img src='".불filename."' width='300'> ".불alt."</center>";
}else $saveDict .= " ".불dict['list3'];
}
//
if($dict['list4']!=''){
if(preg_match("/<img.*/",$dict['list4'])) {
list($url, $alt) = getImgInfo($dict['list4']);
$filename=saveImg($url);
if(preg_match("/.gif/is", $filename)) {
$dict['list4']=str_replace($url, ""$filename"", $dict['list4']);
$saveDict .= $dict['list4'];
}else $saveDict .= "<center><img src='".불filename."' width='300'> ".불alt."</center>";
}else $saveDict .= " ".불dict['list4'];
}
//
if($dict['list5']!=''){
if(preg_match("/<img.*/",$dict['list5'])) {
list($url, $alt) = getImgInfo($dict['list5']);
$filename=saveImg($url);
if(preg_match("/.gif/is", $filename)) {
$dict['list5']=str_replace($url, ""$filename"", $dict['list5']);
$saveDict .= $dict['list5'];
}else $saveDict .= "<center><img src='".불filename."' width='300'> ".불alt."</center>";
}else $saveDict .= " ".불dict['list5'];
}
//
if($dict['list6']!=''){
if(preg_match("/<img.*/",$dict['list6'])) {
list($url, $alt) = getImgInfo($dict['list6']);
$filename=saveImg($url);
if(preg_match("/.gif/is", $filename)) {
$dict['list6']=str_replace($url, ""$filename"", $dict['list6']);
$saveDict .= $dict['list6'];
}else $saveDict .= "<center><img src='".불filename."' width='300'> ".불alt."</center>";
}else $saveDict .= " ".불dict['list6'];
}
//
$saveDict=str_replace('class=', 'style=', $saveDict);
$saveDict=str_replace('id="idiom_list"', 'style="list-style: none;"', $saveDict);
$saveDict=str_replace('id="', 'style="', $saveDict);
$saveDict=preg_replace("/<span style="Definition">(.*?)<\/span>/is", "$1", $saveDict);
$saveDict=preg_replace("/<ul style="">(.\*?)<\/ul>/is", "<span style='font-size: 20px; color: #CC00FF; font-weight: bold;'>$1</span>", $saveDict);
$saveDict=preg_replace("/<span style="color:#444444; padding-left:20px;font-size: 13px">¶<\/span> \*<span style="Use">(.\*?)<\/span>/is", "<div style='color:#444444; padding-left: 20px; font-size: 12px; line-height: 120%'>¶ $1</div>", $saveDict);
saveDict('korea'.불max.'.txt', $saveDict."\n");
$time=date("H:i:s");
echo " $i : $count : $time -".불saveDict;
}
?>
이 프로그램은 HTML에서 데이타를 정확히 클리핑하기 위해 PHP Simple HTML DOM Parser라는 해석기를 이용한다. 따라서 이 어플을 저장한 폴더에 'simple_html_dom.php' 파일도 함께 넣어 두어야 한다. 이 파일은 PHP Simple HTML DOM Parser 사이트에서 'simplehtmldom_1_11.zip'을 내려받으면 구할 수 있다.
클리핑 데이타
위의 어플을 적당한 이름(예: ClippingKSD.php)으로 저장한 뒤 자신이 운영하는 웹 사이트에 올린다. 그리고 [tg=Chrome]크롬/tg과 같은 브라우저로 PHP 프로그램을 호출하면 어플과 같은 폴더에 'koreaNNNNNN.txt'와 같은 파일이 만들어 진다. 생성 모드가 아니라 추가 모드이기 때문에 클리핑 중간에 브라우저가 죽었다면 어플 소스에서 $min 값만 적당한 값으로 바꿔 다시 실행하면 된다.
 클리핑 어플 실행 결과
클리핑 어플 실행 결과
 클리핑된 원시 데이타
클리핑된 원시 데이타
파일의 생성일자를 보면 알 수 있지만 9월 5일 부터 오늘까지 클리핑한 것을 알 수 있다. 5만개씩 6개, 두번을 클리핑했기 때문에 이론상 40시간이 걸린다.
위 그림은 이렇게 클리핑한 원시 데이타이다. 이 데이타를 합치고 스타딕 편집기로 불러와 Build만 하면 사전 파일이 만들어 진다. 다만 처음 어플을 짤 때 고어까지 함께 표시하는 방법을 생각하지 못해 위의 어플을 이용하면 스타일에 'nGulim'이 추가되지 않는다. 또 본문에 포함된 수식이 여러 개면 인터넷 주소가 그대로 남는다. 이런 문제 때문에 어플을 바꾸거나 나중에 EditPlus와 같은 편집기로 한번 다시 가공 해주어야 한다. 다음 그림은 이렇게 재가공된 클리핑 데이타이다.
 재가공된 클리핑 데이타
재가공된 클리핑 데이타
따로 올릴 필요는 없지만 소스를 그대로 이용하면 꼭 '재가공'해 주어야 한다는 것을 강조하기 위해 올렸다.
무서운 저작권법
이런 클리핑 프로그램을 제공하는 것 보다는 '스타딕 사전 파일을 제공하는 것'이 글을 쓰는 나나 사전을 쓸 사람이나 서로 편하다. 그런데 굳이 방법도 복잡한 클리핑 방법을 소개하는 이유는 간단하다. 우리나라의 저작권법이 너무 무섭기 때문이다. '우리나라의 저작권법은 저작자와 사용자 모두를 보호하지 못한다'. 오로지 묻지마 고소를 일삼는 법무법인과 힘있는 사람들에게만 도움이 된다.
그래서 이 사전 파일은 어떤 경우에도 공개하지 않을 생각이다. 삼자 고발까지 가능한 상황이라면 이런 저작권에 문제가 있을 수 있는 파일을 올리는 것 자체가 사이트를 닫는 첩경2이기 때문이다. 따라서 이 사전 파일에 대한 요청도 위 어플과 마찬가지로 받지 않을 생각이다. 또 안면이 있다고 요청해도 줄 생각은 없다. 사전 파일 정보에 필명과 블로그 주소를 넣은 것도 이런 의지를 반영하고 싶었기 때문이다. 따라서 이 사전이 필요한 사람은 직접 클리핑해서 사용하기 바란다.
남은 이야기
크롬, 오페라, 불여우를 이용해서 클리핑을 시도했다. 이 과정에 크롬이 얼마나 신뢰성있는 브라우저인지 다시 한번 확인하는 계기가 됐다. 그 이유는 다음과 같은 상황이 발생했기 때문이다.
2만개의 데이타 클리핑(크롬 6개, 파폭 6개)
총 1000개의 데이타를 클리핑하는데 걸리는 시간은 30분 정도다. 따라서 한시간에 2000개가 가능하다. 2만개는 10시간 분량이고 6개의 탭을 이용했기 때문에 브라우저당 총 12만개를 클리핑하게 된다. 크롬과 불여우로 동시에 걸었기 때문에 총 24만개의 클리핑이 가능하다. 일단 걸어놓고 퇴근한 뒤 확인해 보니 크롬은 12만개를 모두 클리핑했다. 반면 파폭은 오류를 내뱉고 죽어있었다. 즉, 메모리 사용량이 증가하면 서로 다른 프로세스로 동작하는 크롬은 아무 문제 없이 동작했지만 불여우에서는 문제가 생기는 듯 했다.
5만개의 데이타 클리핑(크롬 6개, 오페라 6개)
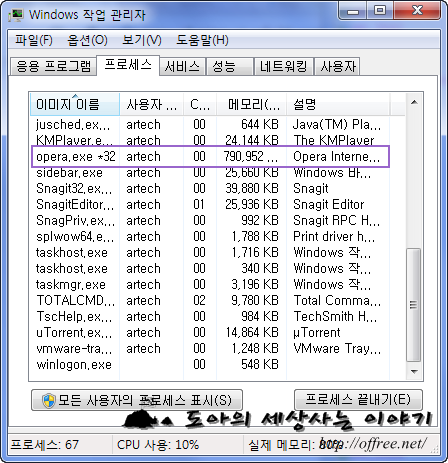
한 시간에 2000개가 가능하기 때문에 5만개의 데이타는 총 25시간이 걸린다. 크롬에 6개 탭으로 1~30만까지를 클리핑하도록 하고 오페라로 30만부터 52만까지 클리핑하도록 했다. 50~52만까지의 데이타는 데이타량이 적기 때문에 전날 완료됐다. 그리고 퇴근한 뒤 출근해 보니 컴퓨터가 장난 아니게 느렸다. 확인해 보니 크롬은 각 프로세스당 200M에서 300M의 메모리를 차지하고 있었고 오페라는 약 1G의 메모리를 차지하고 있었다.
시스템이 너무 느려 일단 크롬을 중지한 뒤 다시 클리핑 하도록 했다. 그리고 지금까지 크리핑된 데이타를 확인해봤다. 크롬으로 클리핑한 데이타는 완벽했다. 클리핑 개수와 빠진 인덱스 모두 일치했다. 그런데 오페라로 클리핑한 자료는 조금 문제가 있었다. 확인해 보니 오페라는 상당히 많은 데이타를 반복 클리핑하고 있었다. 즉 데이타를 요청하다 일정 시간이 지나면 다시 데이타를 요청했기 때문에 발생한 현상으로 보였다. 중요한 것은 모든 데이타를 이렇게 클리핑한 것이 아니라 일부 데이타(35~40만까지, 오페라가 오동작하기 전에 죽은 탭)는 정상적으로 클리핑한 것이 확인되었다.
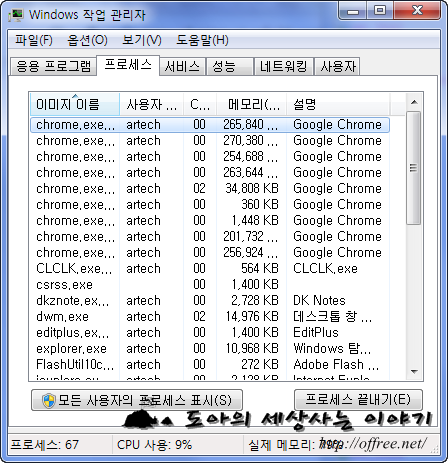
1만개의 데이타 클리핑(크롬 6개, 사파리 4개)
오페라가 실패한 뒤 이번에는 사파리로 해봤다. 기본 엔진이 같기 때문에 괜찮을 것으로 생각했다. 처음에는 사파리도 잘 동작했다. 그리고 시간이 지남에 따라 취소하지 않았는데도 불구하고 데이타를 가져오지 못하는 탭이 있다는 것을 발견했다. 결국 크롬으로 5만개를 모두 클리핑한 뒤 30만 부터 50만까지 크롬으로 다시 클리핑했다. 조금이라도 더 빨리 처리할 욕심으로 여러 브라우저를 사용했지만 결과적으로 브라우저가 죽는 바람에 헛 고생만 한 셈이다. 이래서 크롬을 좋아한다.
마지막으로 파폭으로 시도하기 전에 'Internet Explorer 8'로도 클리핑을 시도했었다. 조건은 파폭과 같았다. 그러나 채 만개도 클리핑하지 못하고 뻗어 버렸다. 이런 브라우저를 쓰는 사람이 조금 불쌍하다3.
- 크롬은 한 서버에 대한 연결을 6개 이상 허용하지 않는다. 따라서 조금이라도 빨리할 욕심에 불여우, 오페라, 사파리등을 이용해서 최대 20개 프로그램을 동시에 돌렸다. 그러나 크롬을 제외하고 끝까지 정상적으로 동작하는 브라우저는 없었다. ↩
- 정치에 관련된 글을 자주 올리기 때문에 더 위험하다. ↩
- 자세한 내용은 크롬, 역시 가장 믿을 수 있는 브라우저를 읽어보기 바란다. ↩